Monitorización
La monitorización es el conjunto de herramientas y procesos con los que mides y gestionas sus sistemas IT. Transforma las métricas en una medición que nos informa de la experiencia de usuario, de que sistemas funcionan mal y que software se está desplegando sin suficiente calidad de servicio.
Los dos clientes de la monitorización son: - El negocio: indicando el valor entregado y la experiencia de usuario. - IT: permite al equipo ténico conocer la calidad de lo entregado y el retorno de la inversión.
Etapas de desarrollo de la monitorización
- Manual: se hace a través de acciones manuales, listas o scripts.
- Reactive: hay recolección de algunas métricas como disco, cpu o memoria o aspectos de rendimiento con herramientas como nagios. Hay gráficas y paneles. Las alertas saltan al email o al chat. Hay datos de experiencia de usuario pero requiere transformación manual para ser útiles. Los checks se ponen como último paso de los despliegues.
- Proactivo: monitorización automatizada. Los errores se arreglan usando información de experiencia de usuario directamente disponible. Las alertas tienen buen contexto y hay escalado. Hay mediciones complejas de experiencia de usuario.
Componentes de la monitorización
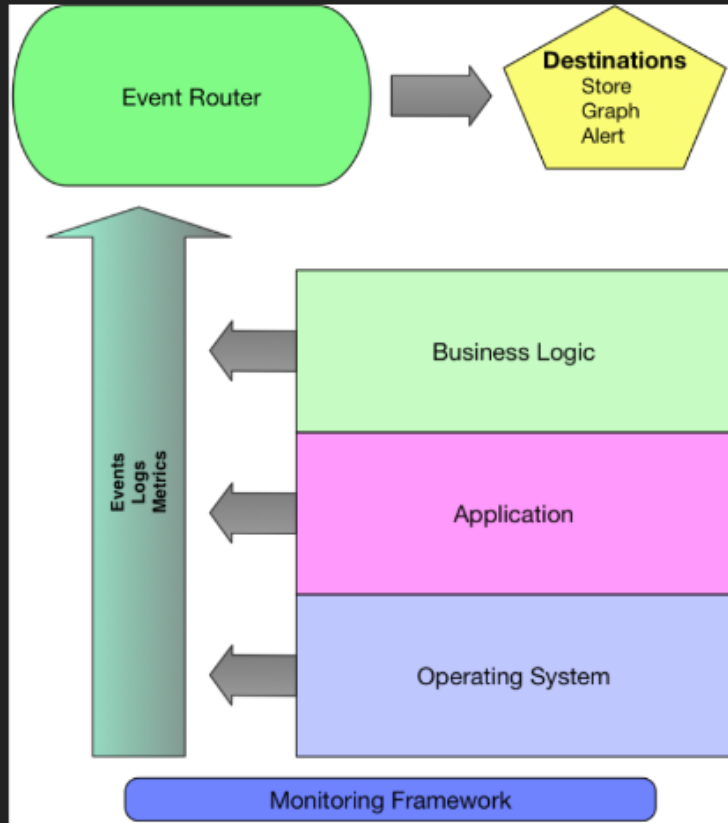
- Nos permite observar el entorno.
- Se basa en eventos, logs y métricas.
- eventos: para informar de cambios
- logs: subconjunto de los eventos. sirven para diagnóstico.
- métricas: nos dan más información y bien usadas son la parte más importante de la monitorización.
- Modelo PUSH: muchos sistemas tradicionales son PULL, por ejemplo Nagios lanza preguntas a los sistemas con checks como un ping ICMP. Cuando hay más sistemas que monitorizar Nagios tiene que escalar en verticla u horizontal. Preferimos un sistema PUSH donde los sistemas envían los datos a un receptor central:
- Logrando así un rendimiento lineal y que los emisores sean simples (no tienen memoria).
- En entornos efímeros no existe el problema en PULL que hay en PUSH, sistema de tan corta vida que no da tiempo a que sean descubiertos.
- Al ser una emisión unidireccional disminuye la superficie de ataque.
- Los sistemas PULL se enfocan en la disponibilidad y la visión de los sistemas como centros de coste (solo tienen que funcionar). El enfoque PUSH permite obtener una visión más rica del valor de los sistema.
- Model Whitebox: el modelo Caja Negra o Blackbox no se preocupa del estado interior de los sistema sino solo de un output concreto. En el modelo que preferimos el sistema envía información de su estado interno y de los componentes de su rendimiento.
Métricas
Las métricas recogen información de un recurso en un intervalos de tiempo que llamaos resolución o granularidad. Demasiada resolución obliga a gastar mucho almacenamiento y muy poco hace la métrica inservible.
Esta información se suele visualizar con una función matemática aplicada como un plot de 2 dimensiones con el tiempo en el eje X y los valores en el eje Y. Las métricas pueden ser: - gauges: contiene un valor que va subiendo y bajando según el estado del recurso. - contador: vañpres que nunca decrecen en el tiempo aunque con una excepción, pueden resetearse a cero. Por tanto pueden resetearse, subir o estar estables. - Temporizadores: informan de la duración que tuvo algo.
El valor de la métrica en sí no es útil sin aplicarle una función Estadística: - count - sum - average - median - percentiles - standard deviation: desviación de la mediana. 0 significa igual que la mediana. - rates of change: cómo de estables son los datos - frecuency distribution, por ejemplo historiogramas
- mean() o average() es que para que sea útil, los datos tienen una Distribución normal|distribución normal.
- median() también limitado a los de distribución normal, es algo más fiable que mean() pero poco más para distribuciones no normales
- desviacion estandar() funciona para distribuciones normales también.